War der „DeepSeek-Schock“ des letzten Jahres nur ein kurzes Beben an der Börse, ist er heute die neue Realität in den IT-Abteilungen. Wir beobachten eine Zäsur: Die Vorstellung, dass nur Unternehmen mit nahezu unendlichem Budget KI-Modelle auf Weltniveau entwickeln können, ist endgültig gefallen.
Die Ökonomie der Intelligenz: 300.000 vs. Milliarden
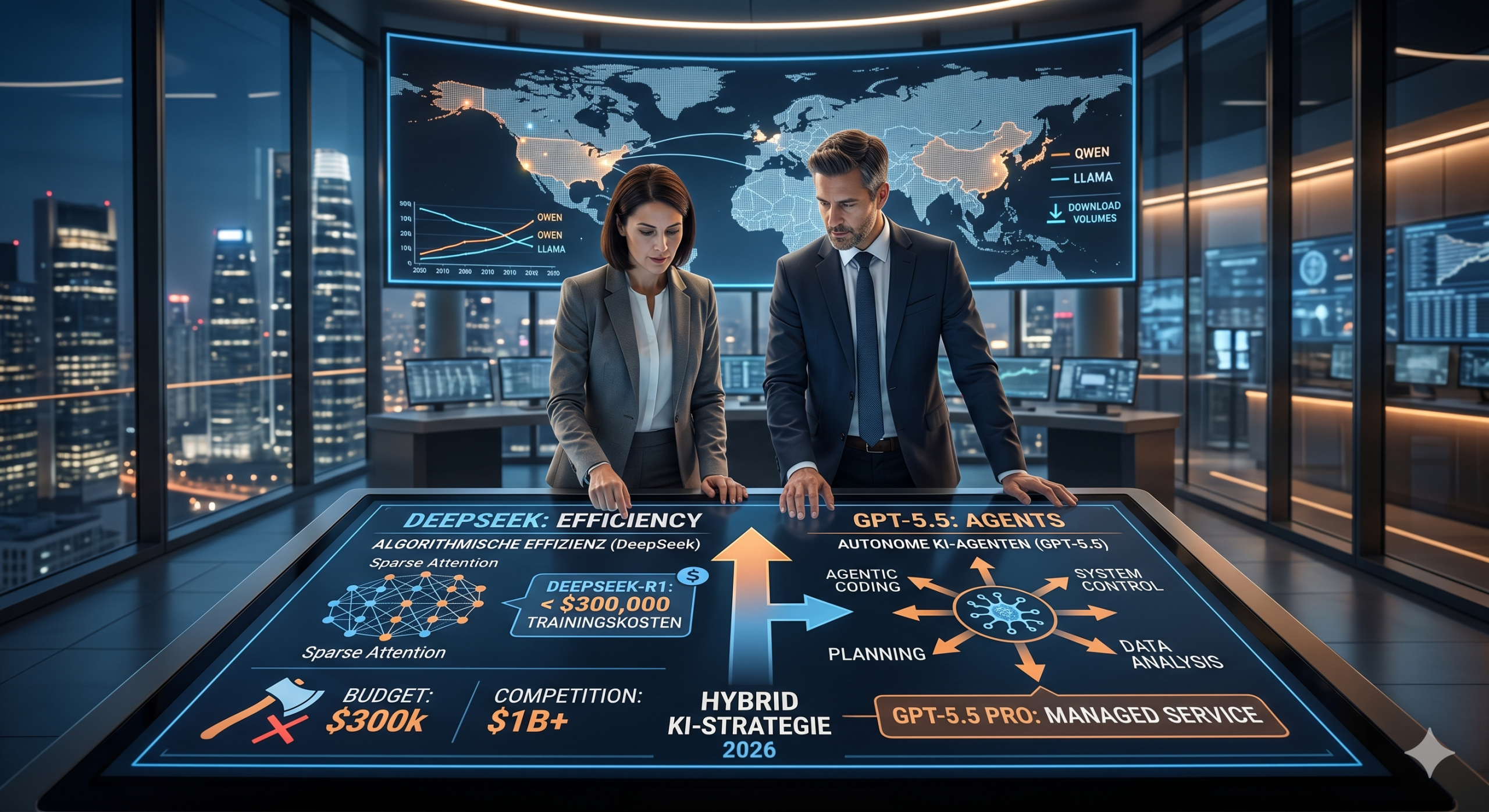
Es ist fast schon amüsant, wenn man die Zahlen betrachtet, die nun im Fachmagazin Nature offiziell bestätigt wurden: Das Training des Reasoning-Modells DeepSeek-R1 kostete weniger als 300.000 US-Dollar. Zum Vergleich: Die US-Konkurrenz investiert Summen, für die mancherorts ganze Infrastrukturprogramme finanziert werden.
Diese Effizienz ist kein Zufall, sondern das Ergebnis intelligenter Architektur. Mit der Einführung von DeepSeek Sparse Attention (DSA) und der Unterstützung von 8-Bit-Gleitkommawerten (FP8) zeigt die neue Generation V4, dass man Rechenleistung chirurgisch präzise einsetzen kann, statt sie mit der Gießkanne zu verteilen. Für IT-Strategie-Verantwortliche bedeutet das: Die Kosten pro Token sinken massiv, während die Leistung bei komplexen Logik-Aufgaben (Reasoning) stabil bleibt.
GPT-5.5 und die Ära der autonomen Agenten
Während die Open-Source-Welt aus Fernost die Preise drückt, flüchtet sich OpenAI mit GPT-5.5 in die funktionale Tiefe. Das Modell versteht sich nicht mehr als Chatbot, sondern als autonomer Mitarbeiter. Mit einer Genauigkeit von über 80 % in komplexen Terminal-Workflows und Bestwerten im agentischen Coding setzt OpenAI dort an, wo die reine Wissensabfrage aufhört.
Interessant ist hierbei die strategische Positionierung: OpenAI baut den „Managed Service“ für komplexe Workflows aus, während DeepSeek und die Qwen-Familie von Alibaba das Betriebssystem der KI-Welt werden. Wer volle Kontrolle und Kosteneffizienz sucht, greift zu Open Weights; wer schlüsselfertige Autonomie benötigt, zahlt den (immer noch deutlich höheren) Preis für die US-Proprietär-Modelle.
Open Source als neuer Industriestandard
Die Zahlen auf Hugging Face lügen nicht: Chinesische Modelle haben bei den Downloadzahlen die Llama-Serie von Meta teilweise überholt. Warum? Weil sie nicht nur günstig, sondern „gut genug“ für 90 % der Anwendungsfälle sind. In der Softwareentwicklung ist der Einsatz von DeepSeek V4 oder Moonshot AI bereits Alltag, da sie bei Coding-Aufgaben oft auf Augenhöhe mit GPT-5.5 agieren – zu einem Bruchteil der API-Kosten.
Dennoch bleibt für IT-Verantwortliche in Europa ein Wermutstropfen: Die Themen Datenschutz und staatliche Einflussnahme sind bei Modellen aus Fernost weiterhin die Elefanten im Raum. Wer diese Modelle nutzt, braucht eine klare Governance-Strategie.
Strategische Empfehlung für 2026
Wir bewegen uns weg von der Suche nach dem „einen, alleskönnenden Modell“. Die Architektur der Zukunft ist hybrid:
Spezialisierte Small Models für lokale Aufgaben und Datenschutz-sensible Prozesse.
Kosteneffiziente Open-Weight-Modelle (wie DeepSeek V4) für Massenanwendungen und Coding.
High-End-Agenten (wie GPT-5.5 Pro) für hochkomplexe Forschungs- und Planungsaufgaben.
Der Markt ist kein Sprint mehr, sondern ein Marathon der Effizienz. Wer heute noch auf die teuerste Lösung setzt, nur weil der Markenname glänzt, hat den Schuss von 2025 nicht gehört.
3 Key Takeaways
Effizienz ist die wichtigste Kennzahl: DeepSeek V4 beweist, dass algorithmische Innovation (Sparse Attention) teure Hardware-Schlachten gewinnt.
Agentic AI wird produktiv: GPT-5.5 verschiebt den Fokus von der Textgenerierung hin zur autonomen Problemlösung in IT-Infrastrukturen.
Open Source dominiert die Basis: Chinesische Modelle wie Qwen und DeepSeek setzen den Standard für Entwickelnde, während US-Modelle sich im Premium-Segment spezialisieren.